


Understanding Data Contracts
What the heck is a data contract and why it's a boon for growth teams!

Hey there,
Welcome and if you haven’t already, you know what to do! 😃
Last week’s post about the need for Growth to understand the language of Engineering and Data was well-received by the community and was included in this week’s
(thanks ).People generally assume that many topics I cover, including today’s, are only for technical audiences to dabble in. I have a different point of view though. I strongly believe that growth practitioners who understand how data and engineering (D&E) teams operate have a huge advantage over those who are indifferent to the needs, workflows, and constraints of their D&E counterparts.
In this post, I’m attempting to explain in simple terms the concept of Data Contracts based on my experience working with software engineers on implementing data pipelines.
Let’s get into it.
The Why
At early or even mid-stage companies, it’s not uncommon for software engineers, rather than data engineers, to build and maintain data pipelines. At Integromat, the first data person – a data generalist – was hired only after we started hitting the limits of what was possible with the existing data infrastructure. We needed someone to take over the maintenance of the data pipelines as Dom and Pete – the engineers who had set them up – had to focus on their software engineering responsibilities.
The core Integromat platform was rearchitected to make the product more scalable, performant, and compliant, and was eventually launched as Make. As you can imagine, it was a massive undertaking that could potentially break all existing data pipelines, directly impacting the downstream tools that relied on the events and properties that originated in the web app.
The above scenario is a rare example of how product changes impact data workflows (I’m not aware of the actual impact since I had moved on from Integromat before the launch of Make).
In reality though, even a tiny change by the engineering team in a product feature, if unaccounted for by the data team, can lead to inconsistent data, or a potential loss of the data pertaining to that feature. Even if the feature isn’t instrumented (its usage isn’t tracked as events), the usage data logged in the production database is impacted.
Let’s look at a scenario:
Linda, a data engineer, has scheduled an ETL job that runs every morning and replicates the data from the production database into an analytical database (a data warehouse) to power an executive report that uses data from the user onboarding survey, which was part of the account creation process.
However, Sid, the software engineer who maintains the user authentication service pushed an update (by merging a pull request he had discussed with his manager) which made the mandatory fields in the onboarding survey optional, making the daily report suddenly look very different.
An executive noticed something was amiss and brought it up in an emergency meeting. As a result, Linda, who was hoping to do some meaningful work, found herself scrambling all day to figure out what caused the data loss, only to find out the next day what caused the issue. Sid, on the other hand, had no idea that performing a simple task he was assigned would cause such a fire drill.
This scenario is rather simple but should help you understand the impact of Engineering workflows on Data workflows.
The figure below illustrates the dependencies between raw data (produced by Engineering), modeled data (produced by Data), and the reports consumed and experiments conducted by Growth.
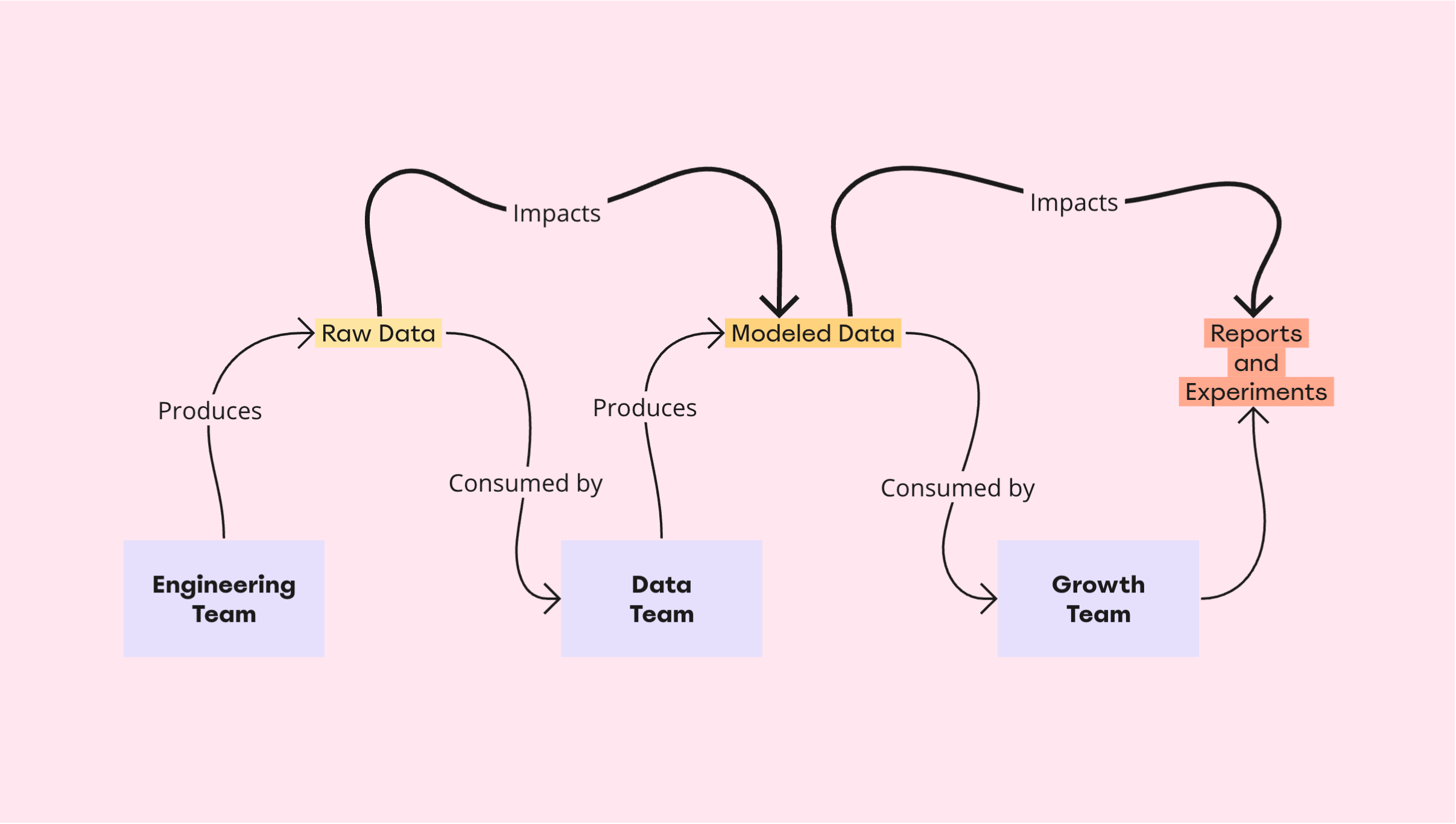
The impact is often inconspicuous and the outcome is usually a fire drill. Therefore, there needs to be a system in place to ensure that any feature change made by Engineering – no matter how seemingly insignificant the change – is communicated to Data before that change is pushed to production. Doing so will enable the data team to account for the changes, make necessary adjustments to the data pipelines, and thereby prevent downstream reports and experiments from being impacted.
Sounds obvious, doesn’t it?
Most people when presented with the notion that the data team must be kept in the loop regarding product changes by the engineering team would assume that this happens already. I certainly didn’t feel the need to spell this out when working with Dom and Pete (the engineers I collaborated at Integromat) and I absolutely took it for granted that they will consider the downstream impact of any change they make upstream. However, in reality, that’s not the case – crazy but true!
Thankfully, some people in data (who must have experienced the disastrous impact of broken pipelines due to upstream changes) became vocal about this problem which led to the emergence of data contracts.
All the articles I saw by ______ on Data Contracts were quite long and not enjoyable to read. I won't say their name, but I do like their content and read it. This was a relatively quick read and got the point across well. I think the natural topic missing here is what data contracts look for small med and large teams. These flows can really slow down velocity, but without them, the alternative is way more costly!
Just another example how company culture and communication standards are pretty fundamental to making a business work!
Me reading this realizing "a data contract is a workflow" not a singular document 🤯 Even though I wouldn't consider myself a data specialist, I love reading these posts because I always come out with a better understanding of something I thought I was too technical for me to grasp.